
地理信息数据分级评价的相对指数熵模型
对表达信息的数据进行分类与分级是人类认识并研究自然的重要方法。在地学研究领域,地理信息数据的分级展示是一个重要的研究问题,既包含地理信息的综合与概括过程,也涉及地理信息的可视化实现。数据分级的主要目的是为了分级后最大限度的保留原始...
- 作者:肖佳,田沁,何宗宜来源:测绘学报|2021年01月11日
对表达信息的数据进行分类与分级是人类认识并研究自然的重要方法。在地学研究领域,地理信息数据的分级展示是一个重要的研究问题,既包含地理信息的综合与概括过程,也涉及地理信息的可视化实现。数据分级的主要目的是为了分级后最大限度的保留原始数据的主要特征,以使得分级结果能够尽可能地反映地理现象的空间分布实质[1]。根据数据分级的本质目的,国内外已经提出了多种不同的分级方法。常用的分级方法包括等差分级、等比分级、标准差分级、分位数分级、自然裂点分级、头尾分割分级等[2-3]。同一原始数据,使用不同分级的方法,得到的结果通常大不相同,因此,有必要对分级结果进行科学的评价。
目前,主要的地理信息数据分级评价方法包括两类:单指标评价模型与混合评价模型。单指标评价模型中,文献[4]根据评价指标的差异,将单指标评价模型分为分级精度评价模型、分级总体精度评价模型和信息量评价模型3类。其中,分级进度评价模型主要基于级内一致性构建评价指标[1];分级总体精度评价模型则依赖级间的差异性构建评价指标[5];信息量评价模型则是根据级间观测数量的差异构建信息熵评价模型[6]。考虑到单指标评价模型分级因素的单一性,有学者提出混合评价模型[7]。文献[8]混合了9个评价指标,以线性组合的方法构建综合性评价指标,但是该模型未量化各指标的权重,用户需要结合自身经验为各指标赋权;文献[4]综合应用3个评级指标,同样以线性组合的方式构建多属性决策分析评价模型,该方法利用信息熵计算各指标的权重,但是熵权的计算受用来对比的分级方案的影响;文献[9]使用5种基本评价指标,同样采用信息熵权重法线性组合这些指标构建混合评价模型。国外对于分级统计地图中的数据分级评价也有大量的研究,通常这些研究都是面向具体的一类数据。文献[10]研究将分级数据的统计指标与空间分布(空间自相关)结合对癌症数据分级进行评价;文献[11]研究了分级统计图中对流行病数据的不同分级方法的评价;文献[12]专门研究了人口密度分级统计图的分级实现与评价;文献[13]提出一种启发式的多指标分级方法,其指标包括了级别的可分性[14]、级内差异性、级间均匀性、分级数量等指标,这种启发式的多因素方法也可以被看作是一种分级评价方法。当前,地理信息数据分级方法与分级结果评价的研究内容趋于一致,即,构建多因素的分级评价指标,除上述研究,近年来国外有相当丰富的研究成果[15-18]。但无论综合何种单评价指标,混合评价模型的评价结果受单评价指标的影响,好的单评价指标能提升混合评价模型的应用水平。
通过以上分析,基于信息量的地理信息数据分级研究的还很少,信息量更多出现在地图信息论的研究中[19],基于地图符号的分类统计,可以定义地图的统计信息量[20];基于地图符号的Voronoi图研究地图几何信息量[21-23]等,这些信息量主要是基于地图符号的各种特征(如统计、几何、拓扑等)来定义。此外,文献[24]从地图信息论研究的角度,利用信息量探讨了地图要素分级数量的问题。与地图信息论的研究对象有所不同,本文主要利用信息熵研究地理信息数据分级的问题,提出一种基于相对指数熵的地理信息数据分级评价模型。该模型从原始数据的级别内聚类水平与级别间离散水平方面共同评价分级结果,顾及了分级数据的级内与级间两个方面;在Python中实现了地理信息数据分级以及分级结果的相对指数熵评价模型;应用5种常用的分级方法,对5种典型分布的6个数据集以及1个人口普查数据集进行了分级试验,分别计算分级结果的相对指数熵,并应用相对指数熵指标对不同分布数据的分级结果进行了评价。
1 指数熵指标 1.1 信息熵
设X是一个随机变量,X的取值为x1、x2、…、xn,并且p(xi)为xi发生的概率,那么香农[25]定义X的信息熵为H(X),数学表达式为
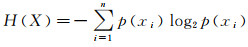 (1)
(1)
式中,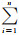
根据式(1)可知,当随机变量X的所有可能取值概率相等,即p(xi)=1/n时,其信息熵H(X)有最大值,即max(H(X))=log2n。但是在实际应用中,由于当p(xi)=0时,香农的熵模型将导致无穷大问题,信息熵将失去意义。为此,有学者[26]提出了指数熵,其数学表达式为
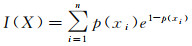 (2)
(2)
式(2)所描述的指数熵,很好地避免了无穷大问题,同时保留了香农熵的可加性。在数据分级问题中,无法避免0值的存在,因此,将使用指数熵来构建分级数据的熵评价模型。与对数熵一样,当随机变量X的所有可能取值概率相等,即p(xi)=1/n时,其指数熵I(X)有最大值,即max(I(X))=e1-1/n。
1.2 级内相对指数熵
设Y={y1, y2, …, ym}为样本容量为m的待分级数据,令D={d1, d2, …, dk}为Y的一个划分,即对于任意d′∈D,有d′≠Ø,且,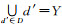
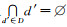
设D={d1, d2, …, dk}是Y的一个有序分级,定义分级D的级内相对指数熵为I(D),数学表达式为
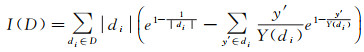 (3)
(3)
式中,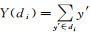
考查式(3),可知级内相对指数熵I(D)反映的是所有级内相对指数熵的和。对于一个级别di,将该级别的相对指数熵表示为I(di),则
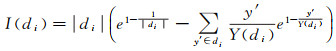 (4)
(4)
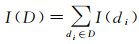 (5)
(5)
考查式(4),一个级别di,可能的最大指数熵与真实指数熵的差,即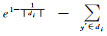
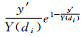
根据指数熵最大化可知,当级别内每个要素,即yd1, yd2, …, ydj∈di概率相等时,即d′={y′, …, y′},则I(d′)=n×
1.3 负值问题及解决
设Y={y1, y2, …, ym}为样本容量为m的待分级数据,在指数熵模型中,概率的值应不小于零,即p(xi)≥0,但是待分级数据,经常出现负数值,如,GDP增长率、人口自然增长率等,因此,需要考虑如何处理原始数据的负值问题。一种简单的方案是将数据进行归一化处理,如,可以令F=(Y-ymin)/(ymax-ymin),其中ymin和ymax为Y中最小元素与最大元素;也可以将原始数据转换为标准正态分布的Z分数之后,再进行归一化处理。但是根据式(3),指数熵函数同时受到样本数据的平均值与方差的影响,归一化将极大影响信息熵的值,因此有必要使用新的方法处理负值问题。
对于Y的一个有序划分D={d1, d2, …, dk},即对于任意i < j,有di≪dj,那么对于任意yi∈di与任意yj∈dj,有yi < yj,那么,在D中,显然最多仅存在一个级别d′中同时包含正数值与负数值。令d′={-y′1, -y′2, …, -y′m, y′m+1, …, y′m+n},然后将d′分为两个划分,分别仅包含正数值与负数值,并且分别对这两个划分进行补0,得到d′-={-y′1, -y′2, …, -y′m}∪{0}和d′+={y′m+1, y′m+2, …, y′m+n}∪{0}。定义该级别d′的级内相对指数熵为
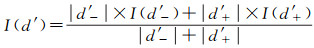 (6)
(6)
式中,|d′-|和|d′+|分别表示两个集合中的元素个数;I(d′-)和I(d′+)可通过式(4)求得。
根据式(6),可以得到有序分级中包含负值的那一个级别的级内相对指数熵,将式(6)代入式(2),并保持其他级别的计算公式不变,则最终的数学表达式为
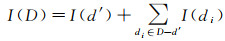 (7)
(7)
式中,d′为同时包含正数值与负数值的一个级别,若d′=Ø,则I(d′)=0,那么式(7)还原为式(5)。
1.4 级间指数熵与相对指数熵评价指标
设Y={y1, y2, …, ym}为样本容量为m的待分级数据,令D={d1, d2, …, dk}为Y的一个有序划分,即,D是Y的一种分级,根据式(4)和式(7),对于D中的任意一个级别di,可得di的级内相对指数熵I(di),定义D的级间指数熵为
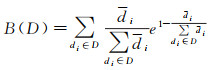 (8)
(8)
式中,di为分级di内所有元素的平均数;di=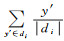
级内相对指数熵I(D),反映了同一级别内部的元素之间的集聚水平,同一级别内元素差异越小,那么其级内相对指数熵值越小,分级效果越好。而级间指数熵B(D),反映了级别之间的离散水平,级间指数熵指标越小,表明分级差异越大,分级效果越好。因此,利用级内相对指数熵与级间指数熵共同构建分级数据的相对指数熵指标,E(D),数学表达式为
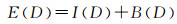 (9)
(9)
分级数据的指数熵指标同时考虑了每个级别内部元素的集聚水平以及不同分级的离散水平,能够综合的反映数据的分级效果,可以用来对不同分级结果进行质量评价。根据级内相对指数熵(I(D))与级间指数熵(B(D))的性质可知,I(D)越小表示级内集聚水平越高,分级效果越好,B(D)越小表示级间离散水平越高,分级效果越好。因此,对于相对指数熵E(D)而言,其值越小表示分级结果越好。
2 试验及分析 2.1 试验数据
为了验证相对指数熵评价模型的有效性,本文选取了5种常用的分级方法,包括等差分级、标准差分级、分位数分级、自然裂点分级、头尾分割分级,进行分级试验。试验数据包括,两组人造数据(完全无界线的数据(表 1)与有明显界线的数据(表 2)),以及2010年美国加利福尼亚州分县人口普查的真实数据(表 3)。为利于数据的对比,保持两组人造数据与真实数据元素数量相等。另外,使用随机生成函数包,生成4种比较典型的统计分布随机数集合,包含均匀分布、正态分布、偏态分布(利用F分布)和指数分布,图 1为这4种分布的概率密度函数,每种统计分布随机生成的数据集元素为10 000个,试验中,将数据都分为5级。应用本文提出的评价模型,对所有分级结果都进行了评价。
表 1 无明显分级界线的数据 Tab. 1 Data with no clear grading line
| 序号 | 值 | 序号 | 值 | 序号 | 值 | 序号 | 值 | 序号 | 值 | 序号 | 值 |
| 1 | —20 | 11 | —10 | 21 | 0 | 31 | 10 | 41 | 20 | 51 | 30 |
| 2 | —19 | 12 | —9 | 22 | 1 | 32 | 11 | 42 | 21 | 52 | 31 |
| 3 | —18 | 13 | —8 | 23 | 2 | 33 | 12 | 43 | 22 | 53 | 32 |
| 4 | —17 | 14 | —7 | 24 | 3 | 34 | 13 | 44 | 23 | 54 | 33 |
| 5 | —16 | 15 | —6 | 25 | 4 | 35 | 14 | 45 | 24 | 55 | 34 |
| 6 | —15 | 16 | —5 | 26 | 5 | 36 | 15 | 46 | 25 | 56 | 35 |
| 7 | —14 | 17 | —4 | 27 | 6 | 37 | 16 | 47 | 26 | 57 | 36 |
| 8 | —13 | 18 | —3 | 28 | 7 | 38 | 17 | 48 | 27 | 58 | 37 |
| 9 | —12 | 19 | —2 | 29 | 8 | 39 | 18 | 49 | 28 | — | — |
| 10 | —11 | 20 | —1 | 30 | 9 | 40 | 19 | 50 | 29 | — | — |
表选项
表 2 有明显分级界限的数据 Tab. 2 Data with clear grading line
| 序号 | 值 | 序号 | 值 | 序号 | 值 | 序号 | 值 | 序号 | 值 | 序号 | 值 |
| 1 | 10 | 11 | 12.1 | 21 | 31.2 | 31 | 100 | 41 | 103.6 | 51 | 1000 |
| 2 | 10.2 | 12 | 12.2 | 22 | 31.5 | 32 | 100.2 | 42 | 300 | 52 | 1001 |
| 3 | 10.5 | 13 | 12.3 | 23 | 32 | 33 | 101 | 43 | 300.4 | 53 | 1 001.5 |
| 4 | 10.7 | 14 | 12.4 | 24 | 32.1 | 34 | 101.4 | 44 | 300.8 | 54 | 1002 |
| 5 | 11 | 15 | 12.6 | 25 | 32.5 | 35 | 101.7 | 45 | 301 | 55 | 1 003.6 |
| 6 | 11.2 | 16 | 30 | 26 | 32.6 | 36 | 102 | 46 | 302 | 56 | 1004 |
| 7 | 11.3 | 17 | 30.2 | 27 | 33 | 37 | 102.3 | 47 | 303.3 | 57 | 1 004.7 |
| 8 | 11.4 | 18 | 30.5 | 28 | 33.1 | 38 | 102.6 | 48 | 304 | 58 | 1 004.9 |
| 9 | 11.6 | 19 | 31 | 29 | 33.5 | 39 | 103 | 49 | 304.6 | — | — |
| 10 | 12 | 20 | 31.1 | 30 | 33.8 | 40 | 103.5 | 50 | 304.8 | — | — |
表选项
表 3 加利福尼亚州分县人口普查数据(2010年) Tab. 3 Census data of California on county level (2010)
| 序号 | 值 | 序号 | 值 | 序号 | 值 | 序号 | 值 | 序号 | 值 | 序号 | 值 |
| 1 | 1175 | 11 | 28 610 | 21 | 87 841 | 31 | 200 849 | 41 | 442 179 | 51 | 1 418 788 |
| 2 | 3240 | 12 | 34 895 | 22 | 94 737 | 32 | 220 000 | 42 | 483 878 | 52 | 1 519 271 |
| 3 | 9686 | 13 | 38 091 | 23 | 98 764 | 33 | 252 409 | 43 | 514 453 | 53 | 1 781 642 |
| 4 | 13 786 | 14 | 44 900 | 24 | 134 623 | 34 | 255 793 | 44 | 685 306 | 54 | 2 035 210 |
| 5 | 14 202 | 15 | 45 578 | 25 | 136 484 | 35 | 262 382 | 45 | 718 451 | 55 | 2 189 641 |
| 6 | 18 251 | 16 | 55 269 | 26 | 150 865 | 36 | 269 637 | 46 | 805 235 | 56 | 2 010 232 |
| 7 | 18 546 | 17 | 55 365 | 27 | 152 982 | 37 | 348 432 | 47 | 823 318 | 57 | 3 095 313 |
| 8 | 20 007 | 18 | 63 463 | 28 | 174 528 | 38 | 413 344 | 48 | 839 631 | 58 | 9 818 605 |
| 9 | 21 419 | 19 | 64 665 | 29 | 177 223 | 39 | 415 057 | 49 | 930 450 | — | — |
| 10 | 28 122 | 20 | 72 155 | 30 | 181 058 | 40 | 423 895 | 50 | 1 049 025 | — | — |
表选项

|
| 图 1 4种分布的概率密度图 Fig. 1 Probability density function diagrams of four distributions |
|
图选项 |
2.2 试验成果与分析
本文在Python中开发了基于相对指数熵的地理信息数据分级评价程序,实现地理信息数据的等差分级、分位数分级、标准差分级、自然裂点分级和头尾分割分级,并基于相对指数熵模型实现分级结果的相对指数熵指标计算。利用上一小节介绍的试验数据,计算了表 1、表 2、表 3中数据分级的相对指数熵指标,结果见表 4、表 5和表 6。表 7列出了4种比较典型的统计分布随机数(应用不同分级方法)分级结果的相对指数熵。图 2采用分级统计图法绘制了表 3中加利福尼亚州分县人口普查数据的5种分级结果。
表 4 无明显分级界线的数据(表 1)分级 Tab. 4 Classification of the data (in Tab. 1) with no clear grading line
| 分级方法 | 等差分级 | 分位数分级 | 标准差分级 | 自然裂点分级 | 头尾分割分级 |
| 第1级 | 1—12 | 1—12 | 1—9 | 1—11 | 1—29 |
| 第2级 | 13—23 | 13—24 | 10—22 | 12—22 | 30—44 |
| 第3级 | 24—35 | 25—35 | 23—36 | 23—34 | 45—51 |
| 第4级 | 36—46 | 36—47 | 37—49 | 35—46 | 52—55 |
| 第5级 | 47—58 | 48—58 | 50—58 | 47—58 | 56—18 |
| I(D) | 6.023 | 5.97 | 6.242 | 6.145 | 6.172 |
表选项
表 5 有明显分级界线的数据(表 2)分级 Tab. 5 Classification of the data (in Tab. 2) with clear grading line
| 分级方法 | 等差分级 | 分位数分级 | 标准差分级 | 自然裂点分级 | 头尾分割分级 |
| 第1级 | 1—41 | 1—12 | 1—30 | 1—15 | 1—41 |
| 第2级 | 42—50 | 13—24 | 31—50 | 16—30 | 42—50 |
| 第3级 | — | 25—36 | — | 31—41 | 51—54 |
| 第4级 | — | 37—47 | — | 42—50 | 55—56 |
| 第5级 | 51—58 | 48—58 | 51—58 | 51—58 | 57—58 |
| I(D) | 3.402 | 3.431 | 2.655 | 1.675 | 3.936 |
表选项
表 6 加利福尼亚州分县人口普查数据(表 3)分级 Tab. 6 Classification of census data (in Tab. 3) of California on county level
| 分级方法 | 等差分级 | 分位数分级 | 标准差分级 | 自然裂点分级 | 头尾分割分级 |
| 第1级 | 1-55 | 1-15 | 1-50 | 1-43 | 1-43 |
| 第2级 | 56, 57 | 16-30 | 51-55 | 44-52 | 44-54 |
| 第3级 | — | 31-44 | 56, 57 | 53-57 | 55-57 |
| 第4级 | 58 | 45-58 | 58 | 58 | 58 |
| I(D) | 6.235 | 5.448 | 6.014 | 4.308 | 4.456 |
表选项
表 7 不同分布分级结果的相对指数熵 Tab. 7 Relative exponential entropies of classification results of different distributions
| 分级方法 | 等差分级 | 分位数分级 | 标准差分级 | 自然裂点分级 | 头尾分割分级 |
| 均匀分布 | 3.025 | 3.027 | 3.035 | 3.034 | 3.089 |
| 正态分布 | 2.232 | 2.237 | 2.231 | 2.235 | 2.238 |
| 偏态分布 | 2.611 | 2.55 | 2.616 | 2.471 | 2.538 |
| 指数分布 | 3.823 | 3.658 | 3.914 | 3.501 | 3.578 |
表选项

|
| 图 2 人口分级图 Fig. 2 Classification map of population |
|
图选项 |
从表 4可以发现,对于无明显界线的数据集,分位数分级得到最优的相对指数熵值,优于其他分级方法,而等差分级所得到的结果与分位数分级的结果差异很小。考查这2种方法的分级结果,发现它们将无界线的均匀分布数据都进行了平均划分,而这种平均划分得到了最优的相对指数熵,这与笔者的感受是一样的。而根据相对指数熵指标,标准差分级与头尾分割分级对于均匀分布数据的分级表现较差,这一结果也通过表 7中均匀分布的标准差与头尾分割分级的相对指数熵结果得到了印证。
表 5结果显示,自然裂点分级方法在处理有明显界线的数据集时,得到最优指数熵值,并且明显优于其他分级。自然裂点分级对于这类数据的分级结果最优,这与很多之前的研究结果是一致的。另外,虽然标准差分级缺失了两级,但是其分级结果的相对指数熵依然优于除自然裂点分级外的其他分级,这表明分级数量并非越多越好。考查表 5中的等差分级与头尾分割分级,发现其差异在于头尾分割分级将等差分级的第5级继续划分成3个级别,但是等差分级结果的相对指数熵反而优于头尾分割分级,等差分级的第5级为{1000, 1001, 1 001.5, 1002, 1 003.6, 1004, 1 004.7, 1 004.9},这一级不应继续进行划分与笔者的感受是相符的。另外根据头尾分割分级的原理,分级过程中通常需要设定头部比例的阈值不应大于0.4,因此,在实际应用中,表 5中的头尾分割分级结果应仅含3级,其结果应与等差分级结果相同。
对于加利福尼亚州分县人口普查数据,表 6结果显示,自然裂点分级方法取得最优的相对指数熵,表现最好,头尾分割分级的相对指数熵结果次优,而等差分级与标准差分级方法表现较差。这个结果也与已有的研究相符,因为该人口普查数据基本符合指数分布类型的肥尾分布,表明使用自然裂点分级与头尾分割分级,对于指数分布的数据能够取得良好的分级效果,而这类数据,明显不适合使用等差分级与标准差分级。指数分布数据比较适合自然裂点分级与头尾分割分级,也得到了表 7中指数分布随机数分级的相对指数熵结果的印证。
在表 7中,均匀分布与指数分布分级的相对指数熵结果与表 4、表 6的结果基本一致,即等差分级与分位数分级适用于均匀分布,其相对指数熵最优;自然裂点分级与头尾分割分级适用于指数分布。对于正态分布,相对指数熵显示标准差分级结果最优,等差分级次优,不过不同分级的相对指数熵差异很小。对于偏态分布,自然裂点分级与头尾分割分级得到的相对指数熵最优,而等差分级与标准差分级得到的相对指数熵结果较差。
本文使用了5种比较典型的数据类型,包括均匀分布(表 1中无明显分级界线的数据符合均匀分布)、正态分布、偏态分布、指数分布(加利福尼亚州分县人口普查数据基本符合指数分布)和有明显界线的数据。结果显示,相对指数熵指标能够很好地评价各种分级方法的分级结果,并且符合人们对于不同数据选取不同分级方法的原则。如,无明显界线的均匀分布数据适用于等差或分位数分级;有明显界限的数据适合采用自然裂点分级,且结果明显优于其他分级方法;通常的指数分布和肥尾分布的数据集可采用自然裂点分级,也可采用头尾分割分级,不适合采用等差分级与标准差分级。对于正态分布数据,相对指数熵显示不同的分级方法差异似乎并不明显;而对于偏态分布的数据,自然裂点分级能够获得较好的效果。总体而言,相对指数熵显示自然裂点分级方法对于不同的分布都取得比较好的分级结果,其分级效果相当稳定。
图 2为加利福尼亚州分县人口普查数据的分级(4级)结果。可以发现,该数据集的自然裂点分级及头尾分割分级两种方法得到的分级结果差异较小,两种分级结果的分级统计图差异也较小。在试验中,本文对数据进行多次微小的改变,这两种方法的分级结果都得到过最优相对指数熵。因此,在具体的分级方法选取中,可以通过指数熵指标,比较分级结果的微小差别,根据不同的数据,选取最优的分级方法。
此外,本文使用分级数据评价研究中[1, 4]经常使用的加权总偏差分级精度(ACU)单指标,评价了上述5种典型分布的7个数据集的不同分级结果(表 8),并与相对指数熵评价进行比较分析。ACU评价指标为
表 8 不同数据分级结果的ACU指标 Tab. 8 ACU indicators of classification results of different data
| 分级数据 | 等差分级 | 分位数分级 | 标准差分级 | 自然裂点分级 | 头尾分割分级 |
| 正态分布 | 0.548 | 0.708 | 0.513 | 0.713 | 0.566 |
| 偏态分布 | 0.243 | 0.706 | 0.209 | 0.611 | 0.555 |
| 指数分布 | 0.191 | 0.649 | 0.182 | 0.518 | 0.429 |
| 平均分布 | 0.648 | 0.647 | 0.603 | 0.65 | 0.444 |
| 无明显界线 | 0.663 | 0.714 | 0.829 | -0.104 | 1.31 |
| 有明显界线 | 0.543 | 0.776 | 0.306 | 0.782 | 0.543 |
| 人口数据 | 0.175 | 0.603 | 0.197 | 0.43 | 0.415 |
表选项
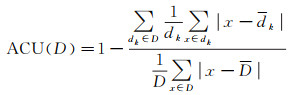 (10)
(10)
式中,符号表示含义与上文相同;dk和D分别表示第k个级别和全体的平均值。
从表 8可以看到,对于正态分布,ACU指标显示自然裂点分级与分位数分级最优;对于偏态和指数分布数据,以及加利福尼亚人口数据,ACU指标得到分位数分级最好;而无明显界线数据,头尾分割分级最优,这不太符合笔者的主观判断。另外,对于无明显界线数据,由于包含正负数值,自然裂点分级的ACU指标为负值,而头尾分割分级ACU指标则超过1。这一结果表明,对于同时包含正负值的数据集,ACU指标是不稳定的。相较而言,相对指数熵指标对于分级结果优劣的判断是符合笔者的主观判断的。
3 结束语
本文提出了一种基于相对指数熵的地理信息数据分级评价模型。通过引入指数熵,定义地理信息数据分级结果的级内相对指数熵与级间指数熵,分别量化同一级别内数据的聚集水平以及不同级别间数据的离散水平,利用级内相对指数熵与级间指数熵共同构建地理信息数据分级的相对指数熵评价指标。由于相对指数熵模型使用原始数据构造概率函数,通过对同一级别中正负数值数据进行分割并补0的方法,处理原始数据中的正负数值同时存在的现象。基于5种典型分布的6个数据集及1个人口普查数据集,采用5种常用的分级方法,对数据进行分级试验并计算相应的指数熵指标。从试验结果上看,针对不同类型的试验数据,相对指数熵指标都能够指示出最优分级方法,如,根据指数熵指标,等差与或分位数分级适用于均匀分布的数据;有明显界限的数据集最宜采用自然裂点分级;指数分布数据适合采用自然裂点分级,也可采用头尾分割分级;正态分布数据宜应用标准差分级,但是与其他分级方法差异较小;偏态分布适合使用自然裂点与头尾分割分级。这都与人们通常的认知是相符的,表明相对指数熵模型是有效的。
本文所提出的相对指数熵模型,可以用于不同分布类型的地理信息数据分级方法的选取与评价,为熵模型在地理信息数据分级方法及分级评价中的研究提供一个思路。不过相对指数熵指标没有考虑空间特征对于分级的影响。未来的研究,将在相对指数熵模型的基础上尝试引入空间特征。
