 RSS����
RSS����A General Method of Detecting Spatial Outlier Distribution Patterns for Point Events
Abstract: Spatial outlier detection is a research hotspot in the domain of spatial data mining. In view of the limitations of existing methods, this paper develops a general method of detecting spatial outlier distribution patterns for point events by considering spatial locations (abbreviated as MCDTSOD), where the definition of spatial outlier is extended and the multi-level constrained Delaunay triangulation is constructed. Firstly, the spatial adjacency relationships are roughly obtained from Delaunay triangulation. Then, three-level constraints are described and utilized for precise spatial adjacency relationships with the consideration of some statistical characteristics. Finally, those spatial point events connected by the remained edges are gathered to form a series of clusters. Those clusters which contain very few point events are regarded as spatial outlier patterns. It can be found that the MCDTSOD is not involved in any parameters. Experiments on both synthetic and real-world spatial datasets are utilized to demonstrate that the MCDTSOD can detect all kinds of spatial outliers with high efficiency.
Key Words��Spatial attribute; Spatial point events; Spatial outlier patterns; Multi-level constrained Delaunay triangulation
��ͼ�������P208 ���ױ�ʶ�룺A
1 ����
���������ռ���Ⱥģʽ̽���ѳ�Ϊ�ռ������ھ��һ����Ҫ�о���֧�������ܹ�ע[1][2]���ռ���Ⱥģʽ̽��ּ�ڴӺ����ռ��������ھ�õ�ƫ�������ֲ��ֲ�ģʽ��С���ֿռ�ʵ�塣�ڵ�����Ϣ��ѧ������ѧ����ᾭ��ѧ��������ռ���Ⱥģʽ��������������������ݣ��ܿ����̺���DZ�ڵġ�δ֪����Ҫ֪ʶ���ɣ������쳣�����¼�̽�⡢������⡢����ͼ����쳣�ֲ���ʵ��Ӧ���з�������Ҫ���á�
Hawkins���������Ⱥ��ĸ�����䶨��Ϊ������ƫ����������Ĺ۲�㣬���������˻��������ɲ�ͬ���Ʋ����ġ�[3]����Կռ����ݵ����ԣ�Shekhar �Ƚ��ռ���Ⱥ�㶨��Ϊ�����ǿռ�������ռ��ڽ���������ʵ����������������������ݼ���Ȳ�����ܲ����ԵĿռ�ʵ�塱[4]�����ǵ��ռ����ݾ��пռ�λ�����Ժͷǿռ�ר�����ԣ��Ӷ��ɽ��ռ���Ⱥģʽ���·�Ϊ���ࣺ�����˼��ռ�λ�����ԵĿռ���Ⱥģʽ����ͬʱ�˼��ռ�λ�����Ժͷǿռ�ר�����ԵĿռ���Ⱥģʽ�����У���һ��ģʽ��ʵ��Ӧ����Ҫ����Կռ���¼������緸����������𡢼��������¼��ȣ�����Ⱥģʽ̽�⣬��������ЩӦ���н����ǿռ���¼��ķ���λ�ã�Ȼ����Դ���ģʽ����ר�ŵ�ϵ�����о���Ϊ�ˣ������Կռ���¼�����ȺģʽΪ�о�����չһ�ֻ��ڲ��Լ��Delaunay��������������̽�ⷽ��-MCDTSOD��
2 ����о��ع˼����ڵ��������
���еĴ�ͳ��Ⱥ��̽�ⷽ���ɴ��·�Ϊ��������ͳ�Ʒֲ��ķ���[5]�������ھ���ķ���[6][7]���������ܶȵķ���[8-10]�������ھ���ķ���[11][12]������ͳ�Ʒֲ��ķ������������ݷ��ӵķֲ�����Ⱥʵ����������������͵ȣ���Ҫ���д����IJ���ʵ����ȷ��ԭʼ���ݵķֲ�������Ӷ����´�����������Բ�ǿ�����ھ����̽�ⷽ�������ݼ���Զ������ʵ��Ķ���ʶ��Ϊ��Ⱥ�㣬����Ҫȱ�����ڽ��Ծ��ȷֲ���������Ч�����ڷǾ��ȷֲ�����������������У��Ҳ����ڷ���ȫ����Ⱥ�㣬��������ƫ��ֲ��ֲ�����Ⱥ�㡣�����ܶȵķ�����Ҫ�Ǹ���ʵ����������ʵ����ܶȲ��춨����ֲ���Ⱥ��LOF�����ڷǾ��ȷֲ�����������Чʶ��ȫ�ֺ;ֲ���Ⱥ�㣬�˺�ܶ�ѧ�߶Դ����������һЩ�Ľ�[9][10]���ܹ��ڸ��Ӹ��ӷֲ������ݼ���̽����Ⱥ�����ȺС�ء����ǣ��������Ҫ�������������������Ҫ��ʵ�����Ⱥ�Ƚ��������������Чʶ���쳣ʵ�塣���ھ���ķ����ǽ��������ֶΣ�����K-means[13]����̽����Ⱥģʽ���÷������������������ѡ��
����������ѧ����Shekhar�Կռ���Ⱥ��Ķ��巢չ��һϵ��̽�ⷽ�����ɴ��·�Ϊ��������ͼ�εķ���[14]�������ھ���ķ���[4][15][16]���������ܶȵķ���[17][18]�������ھ���ķ���[19]��������ģ�͵ķ���[20][21]�����У�����ͼ�εķ����Ǹ��ݿռ��ڽ�ʵ���ľֲ�����Ի��Ʊ����ơ�ɢ��ͼ�ȿ��ӻ�ͼ�������������۹۲�õ������̺��Ŀռ���Ⱥ�㡣�����������Ϊһ��̽���Է�����������ȷ���Զ���ȡ�ռ����ݼ��е���Ⱥģʽ�����ھ���ķ����ͻ����ܶȵķ����Ǵ�ͳ��Ⱥ��̽�ⷽ���ڿռ����ݼ�����չ�����̳��˴�ͳ������ȱ�ݡ����ھ���ķ����ǽ��������в��������κδصĿռ�ʵ��ʶ��Ϊ�ռ���Ⱥ�㣬Ȼ������ҪĿ�����ڷ��ֿռ�أ�̽����Ⱥģʽ����������[19]������ģ�͵ķ�����������������������Ҫ��������ģ�͵ļ��������������ռ����ݷ���ij�ֲַ�������ʵ��Ӧ��������ȷ��ã����ܵ���̽����ƫ��ʵ�������������������ѧ������ͳ��ģ�ͣ������˹�������[20]������ѧϰģ�ͣ���������֯ͼ��[21]����ѧ���߽��пռ���Ⱥģʽ�ھ�
ͨ���������о��ܽ�������Է��֣���ͳ��������չ���ڿռ���¼���Ⱥģʽ̽�⣬������Щ��������ר�����ڿռ����ݼ������ȱ���ռ��ڽ���ϵ�ľ�ȷ���������ҽ�����Ⱥģʽ��Ϊȫ�ֺ;ֲ���Ⱥ��ȱ��ȫ���ԡ��ռ���Ⱥ̽�ⷽ���������ڷ����ǿռ����Բ��죬��ֱ�����ڿռ���¼���Ⱥģʽ��̽�⣬��Ϊ�ռ��ڽ���ϵ�Ķ�������Ⱥģʽ����չ�ṩ����Ҫ˼�롣��ͼ1��ʾ���ֱ�Ϊ����ռ���¼���Ⱥģʽ������ͼ1(a)Ϊȫ����Ⱥģʽ��������ƫ������ֲ��Ŀռ��Ϳռ�أ�ͼ1(b)Ϊ�ֲ���Ⱥģʽ��������ƫ��ֲ��ֲ��Ŀռ��Ϳռ�أ�ͼ1(c)Ϊ��Shekhar����Ŀռ���Ⱥģʽ��������õ����ڲ���Ⱥģʽ��������Ⱥģʽ���ܼ�С�ص���ʽ�����ڿռ��ص��ڲ����������ٵĿռ���¼�ʹ�䲻���Թ���һ���ձ�ۼ�ģʽ������ʵ��Ӧ����������һ����Ҫ����Ⱥģʽ�����磬ij�������¼��ʾ��ȷֲ������ڴ������ڴ��ڽ�С��ģ�Ҳ��ױ����ֵ��ܼ������ص��о���������������������������ֲ��ķ�չ���ɣ�����Ч����DZ�ڴ��ģ�����¼��ķ�����
��Կռ���¼���Ⱥģʽ̽���о����ڵ�����;����ԣ��������ȶԿռ���¼���Ⱥģʽ�������¶��壬�������ڲ��Լ��Delaunay��������չһ�ֿռ���¼���Ⱥģʽ̽��������Է�����MCDTSOD�����潫��MCDTSOD����������ϸ������



(a) ȫ����Ⱥģʽ (b) �ֲ���Ⱥģʽ (c) �ڲ���Ⱥģʽ
ͼ1 �ռ���Ⱥģʽ����
Fig.1 Types of the spatial outliers
3 ���ڲ��Լ��Delaunay�������Ŀռ���¼���Ⱥģʽ̽��
���ȣ��Կռ���¼���Ⱥģʽ���¶���Ϊ���ռ���¼����ݼ���ƫ�������ֲ����ʾۼ��ֲ�ģʽ�Ĺ����㡢ϡ����ܼ���С�Դؼ�Ϊ�ռ���Ⱥģʽ���������˼��ռ���¼����ݼ������ԣ�����Delaunay���������пռ��ڽ���Ĺ����ͱ����������ȫ����Ⱥģʽ���ֲ���Ⱥģʽ���ڲ���Ⱥģʽ�����������ۼ��ֲ�ģʽ�ı����Ի�����ͬ������ȫ����Ⱥģʽ�����������Ͼ��������ۼ�ģʽ��Զ�Ĺ������С�أ����ֲ���Ⱥģʽ���ڲ���Ⱥģʽ��Ӹ��Ӿֲ��IJ��ƫ�������ۼ�ģʽ�Ĺ������С�ء����ڴˣ����Ķ�ԭʼDelaunay������ʩ���������Լ�������ֱ�������ȡȫ����Ⱥģʽ���ֲ���Ⱥģʽ���ڲ���Ⱥģʽ�����������Ҫ�����������裺���Կռ���¼����ݼ�����ԭʼDelaunay��������ʵ�ֿռ���¼����ڽӹ�ϵ�Ĵ��Ա�������δ��������Լ��Delaunay��������ʵ�ֿռ���¼����ڽӹ�ϵ�ľ�ȷ������ռ���Ⱥģʽ�Զ�ʶ�������ÿ�����������ϸ������
��ʼ�ռ����ݼ�����ɢ״̬��ȱ���Կռ�ʵ����ڽӹ�ϵ�ı�����ж�ij�ռ���¼��ڿռ�����;ֲ�ƫ�����ʷֲ�ģʽ�ij̶ȣ���ͨ�������ռ���¼����ڽ�����ʵ�֡�Delaunay���������ݡ����Բ���͡������С��ԭ���������ʷ֣��Ҳ���Ҫ�����κβ�������֤����һ�ֽ����ռ��ʵ����ڽӹ�ϵ����Ч����[22-24]����Delaunay�������ڸ��ӵĿռ����ݼ��в���ȷ�����ռ��ʵ�����ڽӹ�ϵ����ͼ2��ʾ���Ƕ�ģ��ռ����ݼ�������Delaunay���������������ɫ�����ཻ�ı߾�Ϊ���Ե����ߣ�ͨ�����߽������ڽӹ�ϵ�Dz�ȷ�ġ����ڴˣ�����������Delaunay���������Ա���ռ���¼����ڽӹ�ϵ�Ļ����ϣ�ʩ�Ӳ��Լ���������ռ���¼�����ڽӹ�ϵ��

ͼ2 �ռ��ڽӹ�ϵ��Delaunay����������
Fig.2 The spatial neighborhood described by Delaunay������
���Delaunay�������ڱ���ռ���¼����ڽӹ�ϵʱ���ڵ�������⣬�����ȡһ�����ײ��Լ�����Զ�ԭʼDelaunay�������������Ծ�ȷ�����ռ��ڽӹ�ϵ��һЩѧ�����ò�ͬ�ı߳�Լ��ָ���Delaunay�����������������ڿռ�������[23-25]����֤��������Ч�ԡ���ЩԼ��ָ����Թ���Ϊ��
![]() ��1��
��1��
ʽ�У�![]() ��
��![]() �ֱ��ʾ�����е�ƽ���߳��ͱ߳����
�ֱ��ʾ�����е�ƽ���߳��ͱ߳����![]() Ϊ�ɵ��ڵ�ϵ������ΪԤ�賣������Ϊ��߳��仯����ֵ������ָ��Ӹ����������ڴ�ͳ��ֵͳ��������������ʽ�����湹���������Լ��ָ���һ����Ⱥ����ȡָ��ʵ�ֿռ���¼���Ⱥģʽ�IJ��̽�⡣
Ϊ�ɵ��ڵ�ϵ������ΪԤ�賣������Ϊ��߳��仯����ֵ������ָ��Ӹ����������ڴ�ͳ��ֵͳ��������������ʽ�����湹���������Լ��ָ���һ����Ⱥ����ȡָ��ʵ�ֿռ���¼���Ⱥģʽ�IJ��̽�⡣
����1 һ��Լ��ָ�꣺�Կռ���¼����ݼ�SPED����Delaunay�����������Delaunay�����������б߶���һ��Լ��ָ�꣬�ֱ����Ϊ��
![]()
![]() ��2��
��2��
ʽ�У�![]() ΪDelaunay����������һ�ߣ�
ΪDelaunay����������һ�ߣ�![]() Ϊ
Ϊ![]() �ı߳���
�ı߳���![]() ΪDelaunay��������ƽ���߳���
ΪDelaunay��������ƽ���߳���![]() ΪDelaunay�������ı߳����
ΪDelaunay�������ı߳����![]() Ϊ��Ӧϵ����
Ϊ��Ӧϵ����
Delaunay��������ƽ���߳��ͱ߳������ܴӺ�۲�νϺõط�ӳ�ռ���¼����ݼ�������ֲ������Դ����������нϳ��ͽ϶̵ıߡ�Ϊ�˾�ȷʶ��һ������ֲ��еij��ߣ�������Ӧϵ��������ij���ߵij��ȴ���һ������ƽ���߳�������<1����Ӧ��һ��Լ��ָ��ҲԽС����֮Խ��ͨ���˲���ɾ�����г��ȴ���һ��Լ��ָ��ıߣ����Եõ����º�Ŀռ��ڽӹ�ϵ����ͼ3(a)��ʾ�����Կ�����һ�����峤������Чɾ�������ҷ���õ�ȫ����Ⱥ��G2����Ⱥ��G4������ijЩ�ֲ��Դ��ھֲ������Ҫ��������Щ�ֲ���������̺��žֲ����ڲ�����Ⱥģʽ����ͼ3(a)���߿���ʾ��
����2 ����Լ��ָ�꣺����һ�ױ߳�Լ����ÿ���ռ���¼�������º���ڽӵ��¼�����һϵ�еĶ��ֲ��ߣ�����������Ӧָ��Զ��ֲ���ʩ��Լ�����ֱ�����Ϊ��

![]() ��3��
��3��
ʽ�У�![]() Ϊ��ռ�ʵ��
Ϊ��ռ�ʵ��![]() ���ӵľֲ�����
���ӵľֲ�����![]() �ij�Ա��
�ij�Ա��![]() Ϊ
Ϊ![]() �ı߳���
�ı߳���![]() Ϊ�ֲ��ߵ�ƽ���߳���
Ϊ�ֲ��ߵ�ƽ���߳���![]() Ϊ��ԭʼDelaunay����������ͨ���ռ��ڽӹ�ϵ���ɵ��Ӽ�����ͼ3(a)��
Ϊ��ԭʼDelaunay����������ͨ���ռ��ڽӹ�ϵ���ɵ��Ӽ�����ͼ3(a)��![]() ��
��![]() ��
��![]() ��
��![]() ������
������![]() ��
��![]() ������
Ϊ������![]() ���ռ���¼���
���ռ���¼���![]() Ϊ���ռ���¼�
Ϊ���ռ���¼�![]() ��صľֲ��ߵı߳����
��صľֲ��ߵı߳����![]() Ϊ��Ӧϵ����
Ϊ��Ӧϵ����
��һ��Լ����ĸ���ͨ��ͼΪ������Ԫ���ֲ��ߵ�ƽ���߳��ͱ߳�����Ӿֲ���α����˿ռ���¼����ݼ��ڸ����ֲ��ķֲ�ģʽ��ͨ��������Ӧϵ�������ɵľֲ�Լ��ָ���ܺܺõ�ʶ��ֲ��ϳ�����������ֲ��߹���ʹ����Ӧϵ����ƫС������Լ��ָ����Ӧ��С����֮����Ӧϵ����ƫ����Լ��ָ����Ӧ�ϴ�����ɾ��������߳����ڶ���Լ��ָ��ľֲ��ߣ��������¿ռ��ڽӹ�ϵ����ͼ3(b)���߿���ʾ����һ��Լ����Ľ���Աȷ��֣����ھֲ����������ʣ�����õ��������������ҷ���õ��˾ֲ���Ⱥ��G5����Ⱥ��G6����ijЩ�ֲ���Ȼ�������ʹ���ڲ���Ⱥģʽ���õ���ȫ���롣�����Ծֲ��߳�����Ϊ������������ʶ��ֲ��߳�����ϴ������߳��ֲ��Ǿ����������Դ�������ʩ������Լ��ʵ�ֿռ��ڽӹ�ϵ�ľ�ȷ����
����3 ����Լ��ָ�꣺�������϶���Լ��������ÿ���ռ���¼�������º��ڽӵ��¼����ɷֲ���Ϊ���ȵ����ֲ��ߣ�Ϊ��һ��ȷʶ�����ֲ����еľֲ����ߣ�����ͨ��Լ���ռ���¼�������߳�����ʶ��ȫ�ֺ;ֲ��ֲ��Ǿ�������
![]()
![]() ��4��
��4��

![]() ��5��
��5��
ʽ�У�![]() Ϊ�ռ���¼�
Ϊ�ռ���¼�![]() ���ӵ�����߳����
���ӵ�����߳����![]() Ϊ
Ϊ![]() ������ͼ���������¼�������߳�����ϣ�
������ͼ���������¼�������߳�����ϣ�![]() Ϊ��Ӧϵ����ʽ��4���У�
Ϊ��Ӧϵ����ʽ��4���У�![]() Ϊ�ռ���¼�
Ϊ�ռ���¼�![]() ���ڽӵ�����߳������ֵ��
���ڽӵ�����߳������ֵ��![]() Ϊ���ռ���¼�
Ϊ���ռ���¼�![]() ��Ӧ������߳�����ı��
��Ӧ������߳�����ı��![]() Ϊ��Ӧϵ��������ͼ���ռ���¼�����߳�����Ϊ��������ͨ����һ��Լ��ָ��Ͷ���Լ��ָ�����ƵIJ��Զ������Լ�����ҵ���ͼ������߳�����ϴ�ʵ�壬����ʵ�������߳�������Ҫ����������������֮һ��
Ϊ��Ӧϵ��������ͼ���ռ���¼�����߳�����Ϊ��������ͨ����һ��Լ��ָ��Ͷ���Լ��ָ�����ƵIJ��Զ������Լ�����ҵ���ͼ������߳�����ϴ�ʵ�壬����ʵ�������߳�������Ҫ����������������֮һ��
(i) ![]() ��
��
(ii) ![]() ��
��
��Ҫע����ǣ�Ϊ�˱���ȫ�ֲַ������������Ӱ�죬�ڼ���ֲ��ֲ�����������ʶ��ָ��![]() ʱ��������������(i)�ĵ��¼����������ݶ���Լ��ָ��Դ�����¼�������߳�ʩ��Լ����ɾ������ֲ���ͨ������Լ�����������ɹ�����õ��ڲ���ȺģʽG7����ͼ3(c)��ʾ��ͨ����������IJ��Լ�����ԣ����Է���ԭʼDelaunay�������д��ڵ���������嵽�ֲ��IJ���ݱ�����б��������������ջ�ȡ�˾�ȷ�Ŀռ��ڽӹ�ϵ����ͼ3(c)�е��¼�P2��P3��P4����P1�Ŀռ�����
ʱ��������������(i)�ĵ��¼����������ݶ���Լ��ָ��Դ�����¼�������߳�ʩ��Լ����ɾ������ֲ���ͨ������Լ�����������ɹ�����õ��ڲ���ȺģʽG7����ͼ3(c)��ʾ��ͨ����������IJ��Լ�����ԣ����Է���ԭʼDelaunay�������д��ڵ���������嵽�ֲ��IJ���ݱ�����б��������������ջ�ȡ�˾�ȷ�Ŀռ��ڽӹ�ϵ����ͼ3(c)�е��¼�P2��P3��P4����P1�Ŀռ�����



(a) һ��Լ�� (b) ����Լ�� (c) ����Լ��
ͼ3 �ռ��ڽӹ�ϵ�ľ�����
Fig.3 The precise spatial neighborhood
ͨ����ȡ���ռ���¼��侫ȷ�ڽӹ�ϵ�ɵõ�һϵ����ͨ�Ӽ��������һ��̽����Щ��ͨ�Ӽ��еĹ��������Ⱥ�ء�
����4 ��ͨ�Ӽ��������һ�ռ���¼�������ռ�������Ϊ����·�����еݹ���չ������·���ϵ����е��¼�����һ����ͨ�Ӽ�G����ͼ3(c) ��![]() ��
��![]() ��
��
ͨ���ռ������γɵ�һϵ�������������ͨ�Ӽ�DZ���ſռ���¼����ݼ��ĸ��ۼ��ֲ�ģʽ����Ⱥ�ֲ�ģʽ�����ݱ��ĶԿռ���¼���Ⱥģʽ�Ķ��壬���Լ��Delaunay�������Ѿ�ʵ�ֹ����㡢ϡ����ܼ���С�Դ������ʾۼ��ֲ�ģʽ�ķ��룬��˱�����ԡ���С�����Զ�������ָ���һ��ʶ��ռ���¼���Ⱥģʽ��
����5 �ռ���Ⱥģʽʶ��ָ�꣺�Ǹ���ͨ�Ӽ��к��ռ���¼�����ĿΪNi�����ɼ���N�������Լ���N�о�����ͬ��ֵ�ĵ�Ԫ���кϲ��ﵽ�����Ŀ�ģ��Ӷ����������ݼ�N�����������ݼ�N={1, 1, 1, 2, 2, 5, 8, 10}��ͨ����N�г�Ա���з���õ�N�� ={1, 2, 5, 8, 10}���������ݼ�N������ռ���¼���Ⱥģʽָ��Ϊ��
![]()
![]() ��6��
��6��
ʽ�У�Mean(N��)��SD(N��)�ֱ�Ϊ����ͨ�Ӽ������ռ���¼�����������ƽ��ֵ�ͱ����Ϊ��Ӧϵ����Mean(N��)��SD(N��)�ܹ���ӳ����ͨ�Ӽ��е��¼������ķֲ���ͨ����Ӧϵ�������ܹ���Чʶ��������С���Ӽ���N��iԽС��SOIԽ��֮ԽС������ͨ�Ӽ�������С�ڴ�ָ����Ӽ���Ϊ�ռ���Ⱥ�ء�ͼ4(a)��ʾΪ���յõ��ĸ������Ϳռ���¼���Ⱥģʽ��

ͼ4 ����ռ���¼���Ⱥģʽ��ʶ��
Fig.4 The identification of outlier patterns for all types of spatial point events
3.4 �㷨���Ӷȷ���
�� ����Delaunay�������ĸ��Ӷ�ԼΪO(Nlog(N))��
�� Delaunay�������пռ���¼����ڽӵ��¼�����ƽ��ԼΪ6����˶���ʩ������Լ���������ռ�����ĸ��Ӷ��ܺ�ΪO(18N)��
�� ���ݿռ�������еݹ���չ�ĸ��ӶȽ������ԡ�
���Ϸ��������ķ��������帴�Ӷ�ԼΪO(Nlog(N))���ϸߵ�Ч���ܹ���Ӧ��Ч�����ռ亣�����ݼ���
4 ʵ�����
�����������ʵ����֤��������Խ�ԡ��Ƚ��Ժ���Ч�ԡ�ʵ��һͨ��Acrgis10.0���һ�鸴��ģ�����ݼ�����ͼ5��ʾ�������ķ����������K�ڽ����뷨[6]�ͻ����ܶȵ�LOF��[7]���жԱ�ʵ�飬��˵�����ķ�������Խ�ԡ�ʵ�������2008��2010���ҹ���½�����ļ������ض����Ϻ����¼�������վ��ֲ����ݣ���ͼ8��ʾ����ͨ���Դ����ݽ���ʵ�����̽�ⷢ���ҹ��������ļ��������غ����¼��Ŀռ���Ⱥ�ֲ�ģʽ���Ӷ���֤���ķ�����ʵ���ԣ�ͼ9Ϊ���ķ��������־��䷽����̽����������ʵ��������Ⱥ��ģʽ����Ⱥ��ģʽ�ֱ��ò�ͬ���ű�ʾ��
ʵ��������ͨ��ģ��õ���һ�鸴�ӿռ���¼����ݼ�����ͼ5(a)��ʾ�����а�����ȫ����Ⱥ�㡢ȫ����Ⱥ�ء��ֲ���Ⱥ�㡢�ֲ���Ⱥ���Լ��ڲ���Ⱥ��ģʽ�����Ҹ�����Ⱥģʽ����������״���ܶȣ����кܺõĴ����Ժ�˵���ԡ�ͼ5(b)Ϊ�����ڲ��ۼ���Ⱥ��ģʽ���ĸ�������ķŴ���ʾ��
ͼ6��ͼ7�ֱ�Ϊ���ķ���̽�����ͻ���K�ڽ����뷨�������ܶȵ�LOF����̽��������ͼ6��ʵ�������Է��֣����������MCDTSOD�������ܹ��Ӳ����ȷֲ���������Чʶ��ȫ�֡��ֲ��ռ���Ⱥģʽ�����һ��ܹ�̽�������ڿռ�ۼ������쳣�ܼ��ֲ����ڲ��ռ���Ⱥģʽ����Ȼ��ijЩ��Ⱥ��ģʽ�У�����������Ⱥ�ؽṹ���Ҷ��γ�����Ⱥ����Ӵأ������յõ�����Ⱥģʽ��Ԥ�����õĽ����ȫһ�¡����⣬���־��䷽���IJ����������£�Kֵ�ֱ�����Ϊ5��10��15��25����Ⱥ����Ŀ����Ϊ���࣬һ��Ϊ���ڲ���Ⱥģʽ��������Ⱥ�����Ŀ41����һ��Ϊ����Ԥ����Ⱥ����Ŀ85����ͼ7��ʾ������Ⱥ����Ŀ����Ϊ41ʱ������K�ڽ����뷨������Ч̽�������е�ȫ����Ⱥģʽ�����ڷֲ����ӡ��ܶȲ����ȵ�ijЩ�ֲ������������һЩ�ֲ���Ⱥģʽ�������ݷֲ����½��ܼ�Բ�δغ͡�![]() ��״�ظ����ľֲ���Ⱥ�����Ⱥ����ʶ�����⣬����ijЩ�ۼ�ģʽ���硰
��״�ظ����ľֲ���Ⱥ�����Ⱥ����ʶ�����⣬����ijЩ�ۼ�ģʽ���硰![]() ��״������λ�ã��ı߽紦������Ϊ��Ⱥģʽ������K-�����LOF��������Ч̽��ȫ����Ⱥ�㡢��Ⱥ��ģʽ�;ֲ���Ⱥ��ģʽ������ʶ��ֲ���Ⱥ��ģʽ������Ⱥ����Ŀ����Ϊ85ʱ�����ַ�������ʶ���ڲ���Ⱥģʽ�����ǽ��ۼ�ģʽ�����м�Ĵ����δأ��ı߽��ʶ��Ϊ��Ⱥ�㡣
��״������λ�ã��ı߽紦������Ϊ��Ⱥģʽ������K-�����LOF��������Ч̽��ȫ����Ⱥ�㡢��Ⱥ��ģʽ�;ֲ���Ⱥ��ģʽ������ʶ��ֲ���Ⱥ��ģʽ������Ⱥ����Ŀ����Ϊ85ʱ�����ַ�������ʶ���ڲ���Ⱥģʽ�����ǽ��ۼ�ģʽ�����м�Ĵ����δأ��ı߽��ʶ��Ϊ��Ⱥ�㡣


(a) ģ������ (b) �ֲ�����Ŵ���ʾ
ͼ5 ģ�����ݼ�
Fig.5 The simulated dataset


(a) �ռ��쳣�ֲ�ģʽ̽���� (b) �ֲ�����Ŵ���ʾ
ͼ6 ���ķ���̽����
Fig.6 The results obtained by the method proposed in this paper




(i) K=5, N=41 (ii) K=10, N=41 (iii) K=15, N=41 (iv) K=25, N=41




(v) K=5, N=85 (vi) K=10, N=85 (vii) K=15, N=85 (viii) K=25, N=85
(a) ����K�ڽ����뷽��̽����




(i) K=5, N=41 (ii) K=10, N=41 (iii) K=15, N=41 (iv) K=25, N=41




(v) K=5, N=85 (vi) K=10, N=85 (vii) K=15, N=85 (viii) K=25, N=85
(b) ����K-�����LOF����̽����
ͼ7 ������̽�����Ƚ�
Fig.7 The results obtained by different methods
4.2 ʵ��Ӧ��
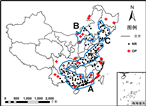
ʵ�����ݼ���Դ�ڹ���������Ϣ�������������ң�������1982-2011��30����й�½������486��վ��Ľ�ˮ�¾�ֵ���ݣ�����վ��ֲ���ͼ8(a)��ʾ������վ����Ծ��ȵطֲ����й��в��Ͷ��������������ɹ���������վ���Ϊϡ�裬��������վ�����Ϊ�ܼ��ֲ��������������ÿ������վ������¼�Ľ�ˮʱ���������ݼ��������ˮָ��SPI��Standardized Precipitation Index����Ȼ�����NDMC��National Drought Mitigation Center����SPIָ���ķ���[26]�����ڱ�1����ʱ��߶�����Ϊ3���£�������3�����ۼƽ�ˮ�����Ӹ�վ������ȡ�ض����Ϻ����¼�����SPI��1.5��������ʱ��㣬���Եõ�ÿ��ÿ�·����ض����Ϻ����¼�������վ�㡣�������ļ������¼�Ϊ�о�������ijվ����ij���6��7��8������һ���µ�SPI��1.5������Ϊ��վ���ڸ����ļ��������ض����Ϻ����¼���������ѡȡ�������ļ������ض����Ϻ����¼�������ֲ���Ϊ�㷺��2008��2010�꣨��ͼ8(b)��(c)��ʾ����Ϊ��Ⱥģʽ̽���ʵ�����ݼ���
��1 ������ˮָ��SPI����
Tab.1 The classification of SPI index
|
�¼����� ���˸ɺ� �ضȸɺ� ��ȸɺ� ���� ��Ⱥ��� �ضȺ��� ���˺��� |
|
SPIָ�� (-��, -2] (-2, -1.5] (-1.5, -1] (-1, 1) [1, 1.5) [1.5, 2) [2, +��) |



(a) �й�����վ��ֲ� (b) 2008���ļ��ض����Ϻ����¼��ֲ� (c) 2010���ļ��ض����Ϻ����¼��ֲ�
ͼ8 ʵ�����ݼ�
Fig.8 The real dataset
��ͼ9(a)��(b)��(c)��ʾ���ֱ�Ϊ���ķ���������K�ڽ����뷨�ͻ���K-�����LOF��ʵ�����ݼ���̽����������NR��ʾ�����ֲ�����OP��ʾ��Ⱥ�㣬OC��ʾ����Ⱥ�ռ�أ����⣬���ں����ַ�����ͨ������ʵ�����ýϼѽ�������2008���ļ��ض����Ϻ����¼��ֲ����ݣ����ķ���̽��õ�4����Ⱥ���7����Ⱥ�ռ�أ���Щ��Ⱥģʽ�ֲ��ں������в������ɹŶ������ӱ��в����������Ρ������غ��Լ������в��ȵ��������⣬�����ֲ���������Դ��·�ΪA��B��C��������������Ⱥģʽ�ֲִ���������������Ĺ�����������Щ��Ⱥģʽ�У����ϵ������м��临�ӵĵ��Σ���������Ϊ�����뺣�ڣ�����ƽԭΪ������˵��Ρ�����ͬʱӰ�콵ˮ���������غ�ͨ��Ϊ̨���½�ҹ�����Ӱ�������ۺ����Ͽ��ܵ����أ���Ϊ���ķ���̽��õ��ĺ����¼���Ⱥģʽ�����������͡�������ͨ���������־��䷽����̽�������Է��֣�����K�ڽ����뷨���Դ���̽���������Ⱥģʽ���������в��������غ��Լ��������в������������˳����������ɾֲ���Ⱥ�أ�����K-�����LOF��̽���������K�ڽ����뷨���ƣ�������ʶ�ֳ������εľֲ���Ⱥ�ء����⣬���ַ�������ȷ̽�������в��ġ���ʽ����Ⱥ�ṹ�����������������ֲ�������д������У��罫�ֲ�ϡ���B����ʶ��Ϊ������Ⱥ�㡣
���2010���ļ��ض����Ϻ����¼��ֲ����ݣ����ķ���̽��õ�7����Ⱥ���7����Ⱥ�ռ�أ���Щ��Ⱥģʽ�ֲ��ں����������Ͷ������������塢�ӱ��в����㽭�������ȵ��������⣬�����ֲ�����ɴ��·�ΪA��B��������������Ⱥģʽ�ֲִ���������������Ĺ��������Լ���Χ�������У������������Ͷ�������ɽ�������������������ļ��ܵ�����ǿ��Ӱ�죬���㽭�������غ���������������½��ȣ��ܺ���̨��Ӱ�����ԡ���Щ������Ϊ������Щ�����ǿ��ˮ������Ⱥģʽ�Ŀ������ء�������ͨ���������־��䷽����̽�������Է��֣����־��䷽�������Ͽ�ʶ�������ᵽ����Ⱥģʽ����ȷ�Ȳ��������ڻ��������������һЩ©��������K-�����LOF��������ʶ��������������ַ��������������ֲ�������д������У��������ܶȷֲ������ȴ���
ͨ��ģ��ʵ���ʵ��Ӧ�÷��������־��䷽��ͨ�����ϵص����������Եõ���Խϼѵ�̽��������ȱ���Կռ���¼�֮���ڽӹ�ϵ�����ܷ������Ӷ����ִ������к�©��������Ҳ����˵���˱�������IJ��Լ��Delaunay���������Ե���Ч�Ժ�ʵ���ԡ����������ķ�����̽�����������о�����������Ⱥģʽ�ĸ��������أ������о��ҹ�����仯���ɡ�Ԥ�⼫�������¼��Ŀռ���Ⱥģʽ������������������ؾ��߾�����Ҫ���塣


(i) 2008�� (ii) 2010��
(a) ���ķ���̽����




(i) 2008��(K=5, N=26) (ii) 2008��(K=10, N=26) (iii) 2010��(K=5, N=40) (iv) 2010��(K=10, N=40)
(b) ����K�ڽ����뷽��̽����



(i) 2008��(K=5, N=26) (ii) 2008��(K=10, N=26) (iii) 2010��(K=5, N=31) (iv) 2010��(K=10, N=31)
(c) ����K-�����LOF����̽����
ͼ9 �쳣�����¼��ռ���Ⱥ�ֲ�ģʽ̽����
Fig.9 The results of spatial outlier distribution patterns of abnormal climate events
5 ������չ��
���������һ�ֻ��ڲ��Լ��Delaunay�������Ŀռ���¼���Ⱥģʽ̽��������Է���-MCDTSOD��ͨ��ʵ��������֣���1��MCDTSOD�����Ƚ���������Ч��̽��������Ϳռ���Ⱥģʽ����2��MCDTSOD����Ҫ��Ϊ�����������������Ӧ�Ժ�ʵ���ԣ���3��MCDTSOD����ʱ�临�Ӷ�ԼΪO(N(logN))������������Ч�ʸߡ�
��һ���Ĺ�������Ҫ�����ڣ���1���˼���ά�ǿռ�ר�����ԵĿռ���Ⱥģʽ�쳣̽�⣻��2���Կռ���Ⱥģʽ����Ч�Խ��ж������������Ķ�̽������������ҪԴ����������֪ʶ����3����չ��ʱ��ά��ʱ����Ⱥģʽ̽�⡣
�� �� �� ��
[1] Pei T, Zhou C H, Luo J C, Han Z J, Wang M, Qin C Z and Cai Q. Review on the proceedings of spatial data mining research. Journal of Image and Graphics, 2001, 6(9): 854-860.
[2] Tan P, Steinbach M, Kumar V. Introduction to data mining [M]. Boston: Addison Wesley Press, 2006.
[3] Hawkins D M. Identification of outliers[M]. London: Chapman and Hall, 1980.
[4] Shekhar S, Lu C T, Zhang P S. A unified approach to detecting spatial outliers[J]. GeoInformatica, 2003, 7(2): 139-166.
[5] Barnett V, Lewis T. Outliers in statistical data[M]. John Wiley & Sons, 3rd ed: Wiley Series in Probability and Statistics, 1994.
[6] Knorr E M, Ng R T. Algorithms for mining distance-based outliers in large dataset[C]. In: Proceedings of the 24th VLDB Conference, New York, USA, 1998: 392-403.
[7] Ramaswamy S, Rastogi R, Shim K. Efficient algorithms for mining outliers from large data sets[C]. In: Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, USA, 2000: 427-438.
[8] Breunig M M, Kriegel H P, Ng R T, et al. LOF: identifying density-based local outliers[C]. In: Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, USA, 2000: 93-104.
[9] Chiu A L M, Fu A C. Enhancements on local outlier detection. In: Proceedings of 7th International Database Engineering and Applications Symposium, 2003: 298-307.
[10] Jin W, Tung A K H, Han J W, Wang W. Ranking outliers using symmetric neighborhood relationship[C]. In: Proceedings of the 10th Pacific-Asia conference on Advances in Knowledge Discovery and Data Mining, Berlin, 2006: 577-593.
[11] Jiang M F, Tseng S S, Su C M. Two-phase clustering process for outliers detection[J]. Pattern Recognition Letters, 2001, 22(6): 691-700.
[12] Al-Zoubi M B, Al-Dahoud A, A. Yahya A. New outlier detection method based on fuzzy clustering[J]. WSEAS Transaction on Information Science and Applications, 2010, 7(5): 681-690.
[13] Macqueen J. Some methods for classification and analysis of multivariate observations[C]. In: Proceedings of 5-th Berkeley Symposium on Mathematical Statistics and Probability. Berkeley, California, 1967: 281-297.
[14] Haslett J, Brandley R, Craig P, et al. Dynamic graphics for exploring spatial data with application to locating global and local anomalies[J]. The American Statistician, 1991, 45(3): 234-242.
[15] Chen D C, Lu C T , Kou Y F, Chen F. On detection spatial outliers [J]. Geoinformatica, 2008, 12:455-475.
[16] ���ǿ, ����, �콨��, ����, ������. һ�ֹ˼��ڽ�����ʵ������Ŀռ��쳣����·���[J]. ң��ѧ��, 2009, 2: 197-202.
[17] Chawla S and Sun P. SLOM: A new measure for local spatial outliers [J]. Knowledge and Information Systems, 2006, 9(4): 412-429.
[18] Ѧ����, ��ʱ��, ��ΰ��, ��ΰ��. �ֲ���Ⱥ���ھ��㷨�о�[J]. �����ѧ��, 2007, 30(8): 1455-1463.
[19] ���ǿ, ����, ���ε�. һ�ֻ���˫�ؾ���Ŀռ�����[J]. ���ѧ��, 2008, 37(4): 482-488.
[20] Chen F, Lu C T, Boedihardjo A P. GLS-SOD: A generalized local statistical approach for spatial outlier detection[J]. In: Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining, New York, USA, 2010: 1069-1078.
[21] Cai Q, He H B, Man H. Spatial outlier detection based on iterative self-organizing learning model[J]. Neurocompuing, 2013, 117: 161�C172.
[22] Tsai V J D. Delaunay triangulations in TIN creation: an overview and a linear-time algorithm[J]. International Journal of Geographical Information Systems, 1993, 7(6): 501-524.
[23] ESTIVILL-CASTRO V, LEE I. Multi-level clustering and its visualization for exploratory spatial analysis[J]. GeoInformatica, 2002, 6(2): 123-152.
[24] ESTIVILL-CASTRO V, LEE I. Argument free clustering for large spatial point-data sets[J]. Computers, Environment and Urban Systems, 2002, 26(4): 315-334.
[25] Deng M, Liu Q L, Cheng T, Shi Y. An adaptive spatial clustering algorithm based on delaunay triangulation[J]. Computer, Environment, Urban and Systems, 2011, 35(4): 320-332.
[26] Hayes M. Drought indices. Available online at: <http://www.drought.unl.edu/whatis/indices.htm>[accessed on 15 February 2003].

